Informed participation is the lifeblood of a healthy democracy. Yet voter ignorance can undermine this, allowing unscrupulous politicians to exploit the electorate. This issue remains pronounced in Philippine politics, as evidenced by the election of controversial figures like Rodrigo Duterte, Ferdinand “Bongbong” Marcos Jr., and Sara Duterte-Carpio.
This article offers a Python-centric guide to hypothetically modeling voter knowledge acquisition over time. By constructing simplified linear and exponential models and simulating events, we can better understand voter ignorance dynamics. The models, though basic, highlight techniques for visualizing and quantifying complex social issues using Python.
Disclaimer: The models presented are hypothetical and do not represent definitive conclusions. Readers are advised to critically assess the information and supplement with other sources.
Defining Our Hypothetical Variables
We will define two hypothetical variables for visualization:
-
X-Axis (‘ignorance_levels’): Represents potential voter ignorance, with 1 meaning extremely uninformed and 10 being very well-informed. This attempts to quantify awareness and engagement.
-
Y-Axis (‘knowledge_gained’): Measures political knowledge hypothetically gained by voters over time through increased participation and learning.
For our model, we assume that as voters educate themselves, their ‘knowledgegained’ increases in a generally upward trajectory. The slope indicates the _hypothetical rate of knowledge acquisition. Steeper slopes imply faster learning.
However, real-world gains often follow a more complex path based on demographics, issues, events, and more. Our simplified models explore potential baseline scenarios.
Building a Linear Model in Python
Let’s start with a basic linear model by plotting straight trendlines for three hypothetical voter groups using Matplotlib:
# Imports
import matplotlib.pyplot as plt
import numpy as np
# X-axis data
ignorance_levels = np.arange(1, 11)
# Slopes for voter groups (m = engagement)
# Arbitrary values for illustration
m1 = 0.1 # Uninformed voters (low engagement)
m2 = 0.5 # Moderately informed voters
m3 = 1.0 # Highly engaged voters
# Y-axis data
uninformed_voters = m1*ignorance_levels
moderately_informed_voters = m2*ignorance_levels
highly_engaged_voters = m3*ignorance_levels
# Plot the lines
plt.plot(ignorance_levels, uninformed_voters, label='Uninformed Voters')
plt.plot(ignorance_levels, moderately_informed_voters, label='Moderately Informed Voters')
plt.plot(ignorance_levels, highly_engaged_voters, label='Highly Engaged Voters')
# Add labels
plt.legend()
plt.xlabel('Level of Voter Ignorance')
plt.ylabel('Political Knowledge Gained')
# Add axis titles to graph
plt.title('Linear Model of Voter Knowledge Growth')
# Display plot
plt.show()
"""
For simplicity, our linear model assumes voters gain political knowledge at a constant rate represented by the slope. However, real-world knowledge gains likely follow a more complex trajectory based on individual experiences.
"""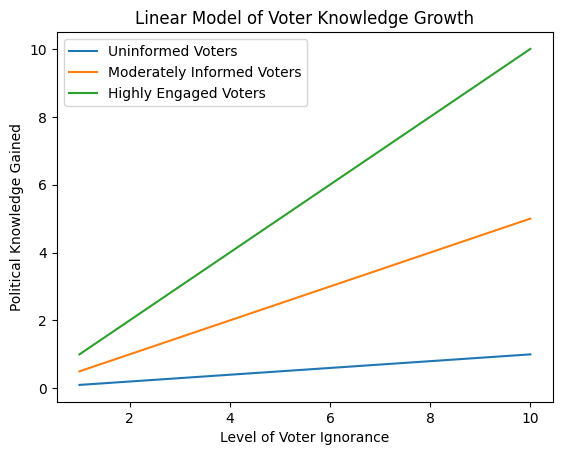 Fig 1. Linear Model of hypothetical voter knowledge growth rates based on engagement levels. For illustration only.
Fig 1. Linear Model of hypothetical voter knowledge growth rates based on engagement levels. For illustration only.
This simplistic model displays the hypothetical difference in knowledge growth rates between groups based on arbitrary engagement values. In reality, many factors influence gains. The linear model offers a basic starting point for analysis.
Modeling Knowledge Acquisition with Exponential Decay
Real-world learning likely follows more of an exponential path, with diminishing returns over time as voters absorb information. We can represent this in Python using a decay factor that controls the curve’s shape:
# Imports
import numpy as np
import matplotlib.pyplot as plt
# X-axis data
ignorance_levels = np.arange(1, 11)
# Model diminishing knowledge gains
# 0.1 decay is arbitrary
def knowledge_gained(levels, decay=0.1):
return 1 - np.exp(-decay*levels)
# Generate y-axis data
knowledge = knowledge_gained(ignorance_levels)
# Plot the exponential model
plt.plot(ignorance_levels, knowledge)
plt.xlabel('Level of Voter Ignorance')
plt.ylabel('Political Knowledge Gained')
plt.title('Exponential Model of Knowledge Growth')
# Use log scale for better visualization
plt.yscale('log')
plt.show()
"""
This model makes the assumption that voters gain knowledge rapidly at first but are subject to diminishing returns over time. The decay factor used is arbitrary and would need to be estimated from real voter data.
"""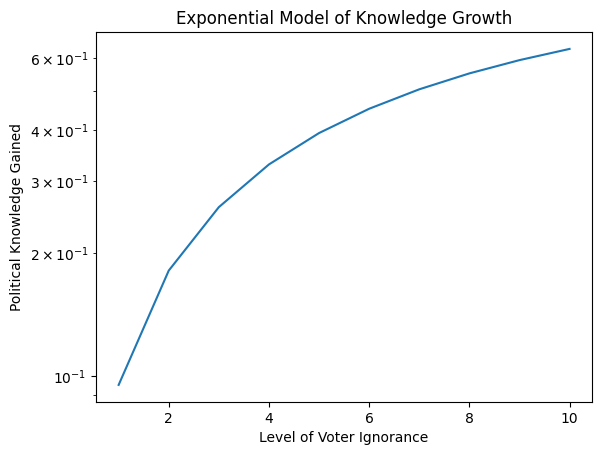 Fig 2. Exponential model of hypothetical voter knowledge gains over time, reflecting diminishing returns. For illustration only.
Fig 2. Exponential model of hypothetical voter knowledge gains over time, reflecting diminishing returns. For illustration only.
This exponential curve exhibits sharper initial gains that gradually taper. However, accurately modeling real voters would require empirical demographic and political data.
Simulating Setbacks to Learning
In the context of the Philippines, we aim to extend our exponential model by simulating hypothetical events that can temporarily hinder voter education. These events may include economic challenges, political issues, disinformation campaigns, and other unforeseen shocks that impact the learning process.
To choose these events, we should ideally draw insights from historical data concerning major incidents that have previously affected voter engagement and knowledge acquisition. Here are some examples tailored to the Philippine context:
-
Economic Crises and Inflation: Periods of economic turmoil and rising inflation can divert voter attention and reduce participation. We can gather GDP data and employ algorithms to identify recession periods and inflation spikes, incorporating them into our simulation.
-
Campaign Promise of Lower Rice Prices: On April 17, 2022, Marcos’ political party Partido Federal ng Pilipinas said he would ensure lower rice prices of P20/kilo if elected president. We can track the narrative and simulate the impact this promise may have on voter perception and engagement.
-
Red-Tagging and Suppression of Freedom of Expression: Instances of red-tagging and restrictions on freedom of expression can deter voters from engaging in political discussions. Analyzing media coverage and legal actions related to these issues can help us identify their influence on voter education.
-
Extrajudicial Killings: Reports of extrajudicial killings can create fear and discourage civic engagement. We can monitor news articles and human rights reports to simulate the impact of such incidents on voter knowledge.
-
Disinformation Campaigns: Disinformation campaigns that spread false narratives can confuse and misinform voters. Natural language processing can assist in detecting and quantifying the effect of these campaigns on voter education.
In our simulation, we will programmatically introduce setbacks at specific timestamps corresponding to these real events. These setbacks can be represented as step changes that temporarily reduce knowledge gains, reflecting how voters might become distracted and misinformed before eventually recovering.
The critical aspect here is selecting events with a historical basis and quantifying their influence on voter engagement. By doing so, we improve the accuracy of our model compared to using random simulated shocks alone.
import numpy as np
import matplotlib.pyplot as plt
def knowledge_gained(levels, decay=0.1):
return 1 - np.exp(-decay*levels)
ignorance_levels = np.arange(1, 100)
knowledge = np.zeros(99)
events = {
"Economic Crisis": {"start": 15, "end": 25, "impact": 0.5},
"Rice Price Promise": {"start": 40, "end": 50, "impact": 0.8},
"Red-tagging": {"start": 65, "end": 75, "impact": 0.6},
"Extrajudicial Killings": {"start": 80, "end": 90, "impact": 0.7},
"Disinformation": {"start": 5, "end": 15, "impact": 0.3}
}
for event, details in events.items():
start = details["start"]
end = details["end"]
impact = details["impact"]
knowledge[start:end] -= impact
plt.plot(ignorance_levels, knowledge)
plt.xlabel('Level of Voter Ignorance')
plt.ylabel('Political Knowledge Gained')
plt.title('Voter Knowledge with Simulated Setbacks')
plt.show()
"""
This simulation simplifies complex real-world events into temporary step changes that hinder knowledge gains. It assumes voters completely recover afterward. In reality, events have more complex long-term influences that would require more sophisticated modeling.
"""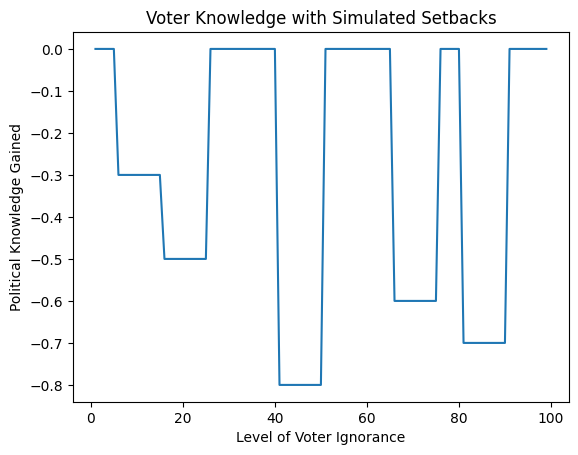 Fig 3. Hypothetical simulation of voter knowledge gains being temporarily impacted by events. For illustration only.
Fig 3. Hypothetical simulation of voter knowledge gains being temporarily impacted by events. For illustration only.
In this simulation, we have incorporated specific hypothetical events tailored to the Philippine context. To enhance the accuracy of our model further, we recommend replacing these hypothetical events with actual historical data as it becomes available.
Understanding How Politicians May Exploit Voter Ignorance
In this section, we discuss how to expand the model to simulate tactics politicians may employ to manipulate less-informed voters:
Emotional Appeals
Politicians often use emotional appeals to bypass rational analysis. We could model this by:
- Defining an “Emotional Appeal Factor” parameter that strengthens emotional decision-making.
- Increasing this parameter when emotional rhetoric is used in simulated speeches or ads.
- Causing it to reduce factual knowledge gains and increase emotive-based choices.
# Emotional appeal factor
emotion_factor = 0.5
# Sample emotional speech
speech = "You must vote for me or the country will suffer!"
# Increase emotional factor
if emotional_speech(speech):
emotion_factor *= 1.1
# Reduce factual knowledge gains
knowledge_gain *= (1 - emotion_factor)Simplification of Complex Issues
We can model oversimplification of issues via:
- An “Issue Complexity Factor” parameter that represents voter perception of how complicated an issue is.
- Lowering this parameter when simplified messaging is used, making issues appear more straightforward.
- Reducing measured knowledge gains related to the oversimplified issue.
For example, we could model oversimplification around a specific issue like inflation. As more simplified messaging is used, the model would progressively lower the “Issue Complexity” parameter for inflation, causing simulated voters to perceive it as easier to understand and make voting choices based on simplistic explanations.
Populist Rhetoric
Populist rhetoric could be simulated by:
- A “Populist Favorability” parameter tracking voter perceptions of a populist candidate.
- Increasing this parameter when populist speech patterns are used.
- Making voters view the populist as highly relatable and aligned with their interests.
Our model could track speech sentiment and vocabulary associated with populist language using NLP. As more populist speech patterns are detected, the simulated voters’ “Populist Favorability” score would increase.
Fearmongering
Fearmongering tactics can be modeled by:
- A “Perceived Threat Level” parameter quantifying voter fear.
- Increasing this parameter when threatening rhetoric is used to scare voters.
- Making fearful voters more reactive and prone to manipulation.
Threatening language could be identified using keyword spotting algorithms. Each fear-based term detected in a speech would increment the population’s “Perceived Threat Level” parameter, making them more susceptible to manipulation.
Confirmation Bias
We can account for confirmation bias by:
- Only exposing simulated voters to information sources that confirm pre-existing beliefs.
- Preventing knowledge gains that contradict long-held positions.
- Reinforcing ignorance of contrary viewpoints and facts.
These examples demonstrate how the model could be enriched to better reflect real-world voter exploitation and manipulation through Python simulation.
Applying Our Models to Understand Voter Behavior
While simplified, these models reveal a few key points about voter learning:
- Informed citizens likely acquire knowledge rapidly, while others may lag - an exploitability gap.
- Real-world gains probably follow exponential decay, with periodic disruptions.
- Voter ignorance seems cyclical as education progresses and regresses. Sustained engagement appears critical.
Policymakers could potentially use these frameworks to estimate the impacts of civics programs and outreach initiatives. But significantly more empirical data is required to strengthen model robustness. Still, Python provides a flexible platform for quantifying voter behavior nuances.
Combating Ignorance and Manipulation
To counter ignorance and combat potential exploitation, some strategies include:
- Comprehensive civics education programs to provide governance and issues background. Python helps track and optimize curriculums based on engagement data.
- Media literacy campaigns to impart critical thinking skills for assessing political rhetoric and mis/disinformation spread. These programs should aim to develop balanced critical faculties without promoting undue cynicism. Python can model these dynamics.
- Election reforms like increased polling locations and grassroots organizing to make voting more accessible. Python enables optimal resource allocation.
- Laws prohibiting voter suppression tactics that disproportionately disenfranchise groups. Python quantifies suppression effects.
- Transparency laws mandating financial disclosures and limiting opaque lobbying. Python facilitates data analysis and visualization.
Targeted interventions require significant additional research. But Python provides a powerful tool for voter behavior modeling and tracking engagements.
Responsible Use of Data Science
When studying voter behavior, we must consider:
- Privacy rights must be protected through anonymization, responsible protocols, and encryption.
- Methodologies should be transparent, with checks against biases. Diverse teams also counteract biases.
- Published models should be evaluated critically rather than accepted definitively.
- Informed consent is essential for ethical data collection.
Good faith efforts uphold fairness and prevent exploitation. With conscientious application, data science like Python can provide insights to promote an informed, engaged citizenry. However, predictive models have inherent uncertainties and cannot capture all nuances.
Conclusion
This article demonstrated using Python to construct hypothetical voter ignorance models, highlighting engagement differences and periodic disruptions. While simplified, these models elucidate techniques for quantifying voter knowledge acquisition. Significantly more empirical research is needed to accurately reflect real-world complexities. Used responsibly, Python enables informed interventions to improve civic participation. But we must thoughtfully apply data science to uphold ethics and avoid manipulation. Ultimately, countering ignorance requires comprehensive engagement efforts, facilitated by tools like Python.