Language model systems have long been confined to a single modality – text. Today, our discussion revolves around the revolutionary approach of OpenAI’s GPT-4 with Vision, a powerful system that allows the model to process images and answer related questions. Broadening the scope of application, GPT-4 with Vision, or GPT-4V, offers developers and machine learning enthusiasts new dimensions to explore.
This guide will provide an overview of GPT-4 with vision, how it works, key capabilities, code examples for using it via the OpenAI API, and considerations for working with this new AI technology.
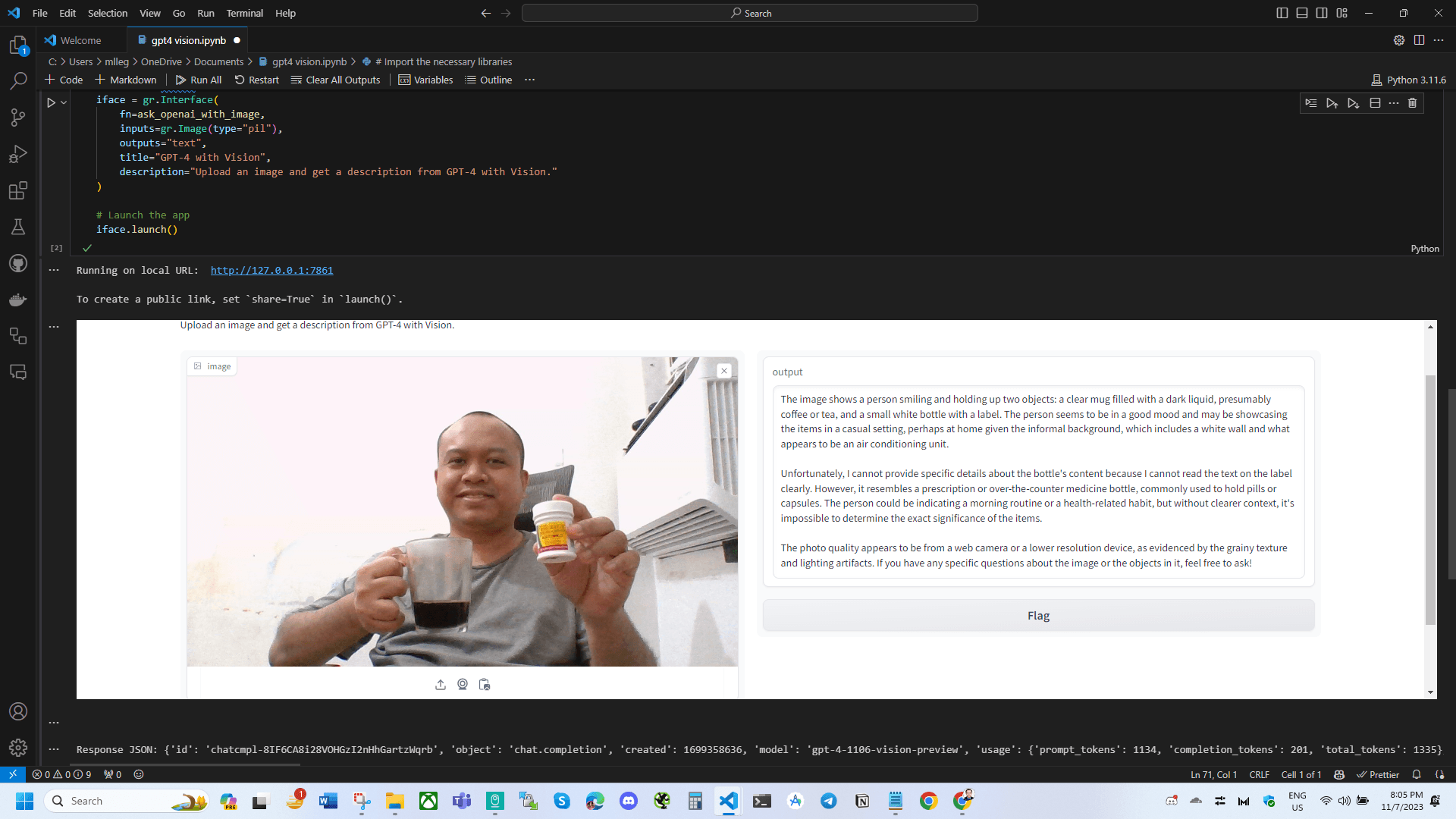
{
"id": "chatcmpl-8IF6CA8i28VOHGzI2nHhGartzWqrb",
"object": "chat.completion",
"created": 1699358636,
"model": "gpt-4-1106-vision-preview",
"usage": {
"prompt_tokens": 1134,
"completion_tokens": 201,
"total_tokens": 1335
},
"choices": [
{
"message": {
"role": "assistant",
"content": "The image shows a person smiling and holding up two objects: a clear mug filled with a dark liquid, presumably coffee or tea, and a small white bottle with a label. The person seems to be in a good mood and may be showcasing the items in a casual setting, perhaps at home given the informal background, which includes a white wall and what appears to be an air conditioning unit. \n\nUnfortunately, I cannot provide specific details about the bottle's content because I cannot read the text on the label clearly. However, it resembles a prescription or over-the-counter medicine bottle, commonly used to hold pills or capsules. The person could be indicating a morning routine or a health-related habit, but without clearer context, it's impossible to determine the exact significance of the items.\n\nThe photo quality appears to be from a web camera or a lower resolution device, as evidenced by the grainy texture and lighting artifacts. If you have any specific questions about the image or the objects in it, feel free to ask!"
},
"finish_details": {
"type": "stop",
"stop": null
},
"index": 0
}
]
}GPT-4 with Vision: An Overview
GPT-4 with Vision is a version of the GPT-4 model designed to enhance its capabilities by allowing it to process visual inputs and answer questions about them. The vision model – known as gpt-4-vision-preview – significantly extends the applicable areas where GPT-4 can be utilized.
It is crucial to understand certain facts about GPT-4 with Vision. First, it does not deviate much from the behavior of GPT-4. Second, it doesn’t perform any worse at text tasks as it simply augments the existing GPT-4 with vision capacity. Lastly, it delivers an augmented set of capabilities for the model.
The GPT-4 with Vision model adds the ability to understand visual content to the existing text-based functionality of GPT models. This is a significant step forward, as it allows for more diverse applications of these models, including tasks like image captioning, visual question-answering, or even understanding documents with figures.
Key Capabilities
Some of the key capabilities unlocked by adding vision to GPT-4 include:
- Image captioning - Generating coherent natural language descriptions of image contents.
- Visual question answering - Answering text-based questions about images.
- Multimodal reasoning - Making logical inferences and connections using both text and visual inputs.
- Image generation - Describing or captioning imagined images not provided as inputs.
- OCR for text extraction - Recognizing and extracting text from images.
- Improved language grounding - Anchoring language more strongly to visual concepts.
- Multimodal summaries - Summarizing documents or passages that contain images as well as text.
- Creative writing aids - Using imagined pictures described in text to improve descriptions in creative writing.
While impressive, GPT-4 with vision does have limitations. It is not optimized for precise object localization or counting. Performance can suffer on rotated, blurry or obscured images. And it is not a specialist for niche image domains like medical scans. But its capabilities are rapidly improving with more training.
Quick Start with Python
To get started with GPT-4 with Vision in Python, we first need to send an image to the model. This can be achieved in two primary ways: by passing either a link to the image (image_url) or the image directly as a base64 encoded string in the request. The encoded image or image URL can be passed in user, system, and assistant messages.
Let’s proceed with a Python example illustrating the basic setup of utilizing the GPT-4V model. We will use Python’s requests module to make an HTTP request to the OpenAI API, passing the gpt-4-vision-preview model, a user message comprising the image_url and a question about the image, and specify a max_tokens limit:
import requests
import os
import openai
openai.api_key = os.getenv('OPENAI_API_KEY')
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {openai.api_key}"
}
payload = {
"model": "gpt-4-vision-preview",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "I've uploaded an image and I'd like to know what it depicts and any interesting details you can provide."
},
{
"type": "image_url",
"image_url": "https://www.rappler.com/tachyon/2022/06/people-we-lost-under-Duterte-1.jpg"
}
]
}
],
"max_tokens": 4095
}
response = requests.post("https://api.openai.com/v1/chat/completions", headers=headers, json=payload)
print(response.json())Image Source: Rappler
In this request’s context, GPT-4 with Vision processes the queried image and returns an interpretation of the image’s primary content.
{
"id": "chatcmpl-8IEByXFYNYKlvHBC9Hla31AEPjyCb",
"object": "chat.completion",
"created": 1699355150,
"model": "gpt-4-1106-vision-preview",
"usage": {
"prompt_tokens": 1134,
"completion_tokens": 199,
"total_tokens": 1333
},
"choices": [
{
"message": {
"role": "assistant",
"content": "The image you've provided appears to show a group of activists preparing for a protest or awareness campaign. The individuals in the image are holding and arranging placards with various slogans such as \"Defend Environmental Defenders,\" \"Stop the Killings,\" and \"Punish the Bigots and Protectors.\" The placards suggest that the protest is focused on environmental protection and human rights, specifically calling attention to violence against environmental activists and the need for accountability.\n\nThe overall mood is one of urgency and activism, as evidenced by the bold lettering and the red and blue color scheme which often represents danger and alertness. The background seems to be a textured wall or possibly a digital overlay or projection with similar messages reinforcing the theme of the protest.\n\nThe image captures a moment of preparation and seems to convey a serious message about protecting those who work to safeguard the environment and opposing violence and impunity. It reflects the broader global concern for environmental justice and the risks faced by those on the frontline of environmental advocacy."
},
"finish_details": { "type": "stop", "stop": "<|fim_suffix|>" },
"index": 0
}
]
}Working with Base64 Encoded Images
In addition to directly using URLs, GPT-4V supports Base64 encoded images. In Python, this can be achieved using the built-in base64 library. First, open the image and read it as a binary stream. Then, encode this binary data to base64, get the JSON response by sending a POST request to the OpenAI API:
import base64
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
base64_image = encode_image("path_to_your_image.jpg")
payload['messages'][0]['content'][1]['image_url'] = f"data:image/jpeg;base64,{base64_image}"
response = requests.post("https://api.openai.com/v1/chat/completions", headers=headers, json=payload)
print(response.json())When working with multiple images, repeat the image insertion in the content list of your payload.
Multiple Images
We can provide multiple img_url and img_b64 parameters to have the model process several images:
response = openai.Completion.create(
img_url=[
"https://image1.com",
"https://image2.com"
],
img_b64=[base64_str1, base64_str2]
)The prompt can reference image1, image2 etc. GPT-4 will interpret all provided images.
Image Sizes
OpenAI recommends image inputs be under 1 MB and no larger than 1024x1024 pixels for performance. But other sizes are supported.
Controlling Detail Level
The detail parameter controls fidelity of image interpretation:
low(default): 512x512 resolution, fast processinghigh: up to 1024x1024 resolution, slower processing
For example:
response = openai.Completion.create(
#...,
detail='high'
)GPT-4 Vision Demo with Gradio
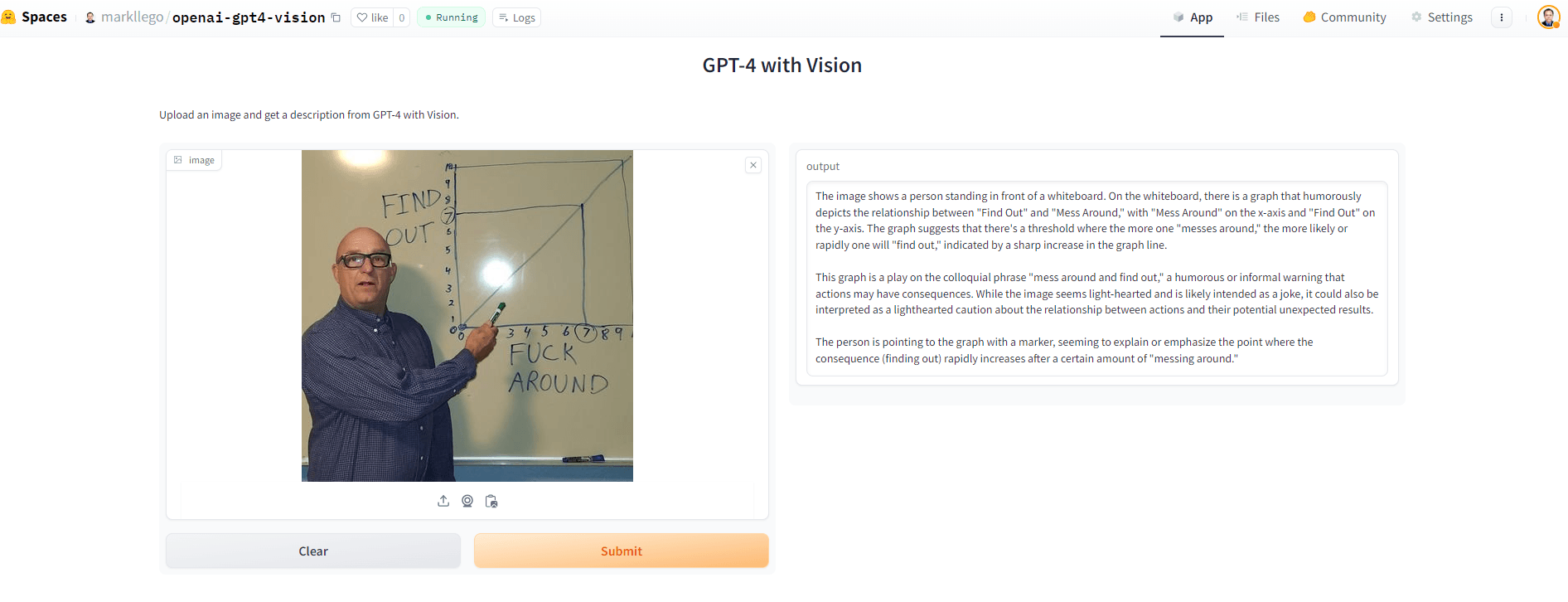
To see GPT-4 with vision in action, I created a live demo using the Gradio and deployed it via Hugging Face Spaces.
The full source code is as follows:
# Import the necessary libraries
import gradio as gr
import openai
import base64
import io
import requests
# Function to encode the image to base64
def encode_image_to_base64(image):
buffered = io.BytesIO()
image.save(buffered, format="JPEG")
img_str = base64.b64encode(buffered.getvalue()).decode("utf-8")
return img_str
# Function to send the image to the OpenAI API and get a response
def ask_openai_with_image(api_key, instruction, json_prompt, low_quality_mode, image):
# Set the OpenAI API key
openai.api_key = api_key
# Encode the uploaded image to base64
base64_image = encode_image_to_base64(image)
instruction = instruction.strip()
if json_prompt.strip() != "":
instruction = f"{instruction}\n\nReturn in JSON format and include the following attributes:\n\n{json_prompt.strip()}"
# Create the payload with the base64 encoded image
payload = {
"model": "gpt-4-vision-preview",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": instruction,
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
"detail": "low" if low_quality_mode else "high",
},
},
],
}
],
"max_tokens": 4095,
}
# Send the request to the OpenAI API
response = requests.post(
"https://api.openai.com/v1/chat/completions",
headers={"Authorization": f"Bearer {openai.api_key}"},
json=payload,
)
# Check if the request was successful
if response.status_code == 200:
response_json = response.json()
print("Response JSON:", response_json) # Print the raw response JSON
try:
# Attempt to extract the content text
return response_json["choices"][0]["message"]["content"]
except Exception as e:
# If there is an error in the JSON structure, print it
print("Error in JSON structure:", e)
print("Full JSON response:", response_json)
return "Error processing the image response."
else:
# If an error occurred, return the error message
return f"Error: {response.text}"
json_schema = gr.Textbox(
label="JSON Attributes",
info="Define a list of attributes to force the model to respond in valid json format. Leave blank to disable json formatting.",
lines=3,
placeholder="""Example:
- name: Name of the object
- color: Color of the object
""",
)
instructions = gr.Textbox(
label="Instructions",
info="Instructions for the vision model to follow. Leave blank to use default.",
lines=2,
placeholder="""Default:
I've uploaded an image and I'd like to know what it depicts and any interesting details you can provide.""",
)
low_quality_mode = gr.Checkbox(
label="Low Quality Mode",
info="See here: https://platform.openai.com/docs/guides/vision/low-or-high-fidelity-image-understanding.",
)
# Create a Gradio interface
vision_playground = gr.Interface(
fn=ask_openai_with_image,
inputs=[
gr.Textbox(label="API Key"),
instructions,
json_schema,
low_quality_mode,
gr.Image(type="pil", label="Image"),
],
outputs=[gr.Markdown()],
title="GPT-4-Vision Playground",
description="Upload an image and get a description from GPT-4 with Vision.",
)
# Launch the app
vision_playground.launch()You can try out the live demo yourself here: https://huggingface.co/spaces/markllego/openai-gpt4-vision
The full source code is also available on GitHub.
This provides a simple way for anyone to experiment with providing images to GPT-4 and see it generate descriptions in real-time. The source code shows how to securely call the OpenAI API from Python, handle images, and build an interface with Gradio.
Understanding GPT-4 with Vision’s Limitations
Like any AI model, GPT-4V has its limitations:
- It is not recommended for interpreting specialized medical images such as CT scans.
- Languages using non-Latin characters might not be adequately interpreted.
- It may misinterpret upside-down or rotated texts.
- GPT-4V may struggle with tasks requiring precise spatial localization.
- It may generate incorrect descriptions or captions in certain scenarios.
Taking these limitations into account will help achieve the best model performance.
Conclusion
GPT-4 with Vision offers developers an exciting opportunity to expand the capabilities of their applications by integrating visual understanding into their workflows. Although it can handle many tasks, it’s essential to continuously be aware of its limitations. This guide provides a Python-oriented method for integrating vision-based capabilities of GPT-4 into Python applications, serving as a foundation for deeper exploration of OpenAI’s GPT-4 with Vision and how it can be utilized to create more sophisticated models and applications.
The potential of GPT-4 with Vision is vast. From natural language processing, textual question answering to visual skills, these advancements augment AI capabilities and open new domains of applications and research avenues to explore. This guide serves as an introduction to Python developers, data scientists, machine learning engineers, and computer science students to start their journey with OpenAI’s GPT-4V.